
Amazon S3 Intelligent-Tiering – Improved Cost Optimizations for Short-Lived and Small Objects
 |
In 2018, we first launched Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering). For customers managing data across business units, teams, and products, unpredictable access patterns are often the norm. With the S3 Intelligent-Tiering storage class, S3 automatically optimizes costs by moving data between access tiers as access patterns change.
Today, we’re pleased to announce two updates to further enhance savings.
- S3 Intelligent-Tiering now has no minimum storage duration period for all objects.
- Monitoring and automation charges are no longer collected for objects smaller than 128 KB.
How Does this Benefit Customers?
Amazon S3 Intelligent-Tiering can be used to store shared datasets, where data is aggregated and accessed by different applications, teams, and individuals, whether for analytics, machine learning, real-time monitoring, or other data lake use cases.
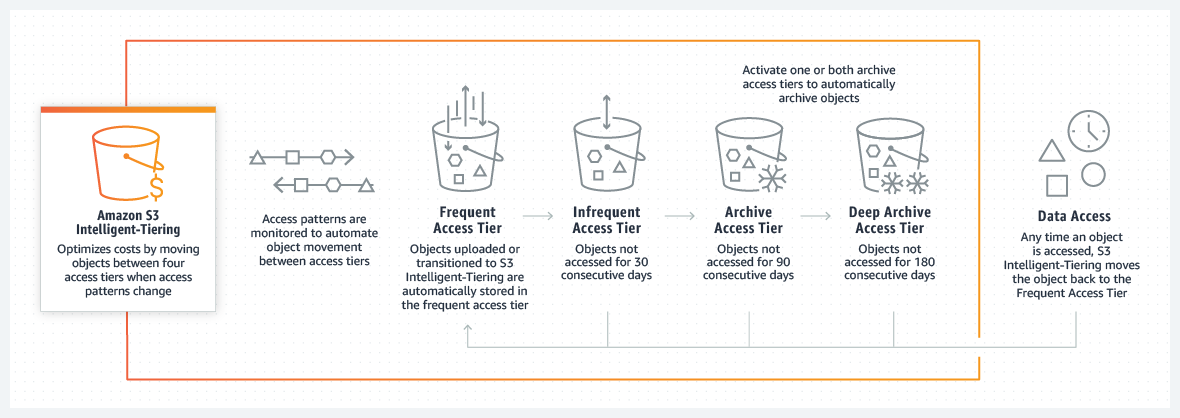
With these use cases, it’s common that many users within an organization will store data with a wide range of objects and delete subsets of data in less than 30 days.
To date, S3 Intelligent-Tiering was intended for objects larger than 128 KB stored for a minimum of 30 days. As of today, monitoring and automation charges will no longer be collected for objects smaller than 128 KB — this includes both new and already existing objects in the S3 Intelligent-Tiering storage class. Additionally, objects deleted, transitioned, or overwritten within 30 days will no longer accrue prorated charges.
With these changes, S3 Intelligent-Tiering is the ideal storage class for data with unknown, changing, or unpredictable access patterns, independent of object size or retention period.
How Can I Use This Now?
S3 Intelligent-Tiering can either be applied to objects individually, as they are written to S3 by adding the Intelligent-Tiering header to the PUT request for your object, or through the creation of a lifecycle rule.
One way you can explore the benefits of S3 Intelligent-Tiering is through the Amazon S3 Console.
Once there, select a bucket you wish to upload an object to and store with the S3 Intelligent-Tiering class, then select the Upload button on the object display view. This will take you to a page where you can upload files or folders to S3.
You can drag and drop or use either the Add Files or Add Folders button to upload objects to your bucket. Once selected, you will see a view like the following image.

Next, scroll down the page and expand the Properties section. Here, we can select the storage class we wish for our object (or objects) to be stored in. Select Intelligent-Tiering from the storage class options list. Then select the Upload button at the bottom of the page.

Your objects will now be stored in your S3 bucket utilizing the S3 Intelligent-Tiering storage class, further optimizing costs by moving data between access tiers as access patterns change.
S3 Intelligent-Tiering is available in all AWS Regions, including the AWS GovCloud (US) Regions, the AWS China (Beijing) Region, operated by Sinnet, and the AWS China (Ningxia) Region, operated by NWCD. To learn more, visit the S3 Intelligent-Tiering page.
What is your reaction?


You may also like

AWS Weekly Roundup: AWS Developer Day, Trust Center, Well-Architected for Enterprises, and more (Feb 17, 2025)

AWS CloudTrail network activity events for VPC endpoints now generally available
